Aggregation, deduplication and validation of service data DRAFT
- The problem
- Publishing
- Deduplication
- Responsibilities of data custodians
- Appendix A - Pertinent user stories
The problem
The OpenCommunity Discovery report says:
“A standard could solve the problem of artificial boundaries. But it will solve it if, and only if, directories are adapted to pull in service data from other councils’ directories.”
The same is true for directories from other sectors relating to other geographical boundaries. Hence, the same service may be described by different publishers in different areas (nationally, regionally and locally) and in different sectors (dementia, health, recreation, …). We need to avoid that service appearing more than once in a trusted aggregated directory and to know which entry is the one to which people should be directed, as opposed to other duplicates.
The flow chart below illustrates a simplified scenario in which a single AgeUK service is described centrally by AgeUK which may be seen as a trusted service provider. These service details are imported by two directories but duplicated by local entries in two other directories.
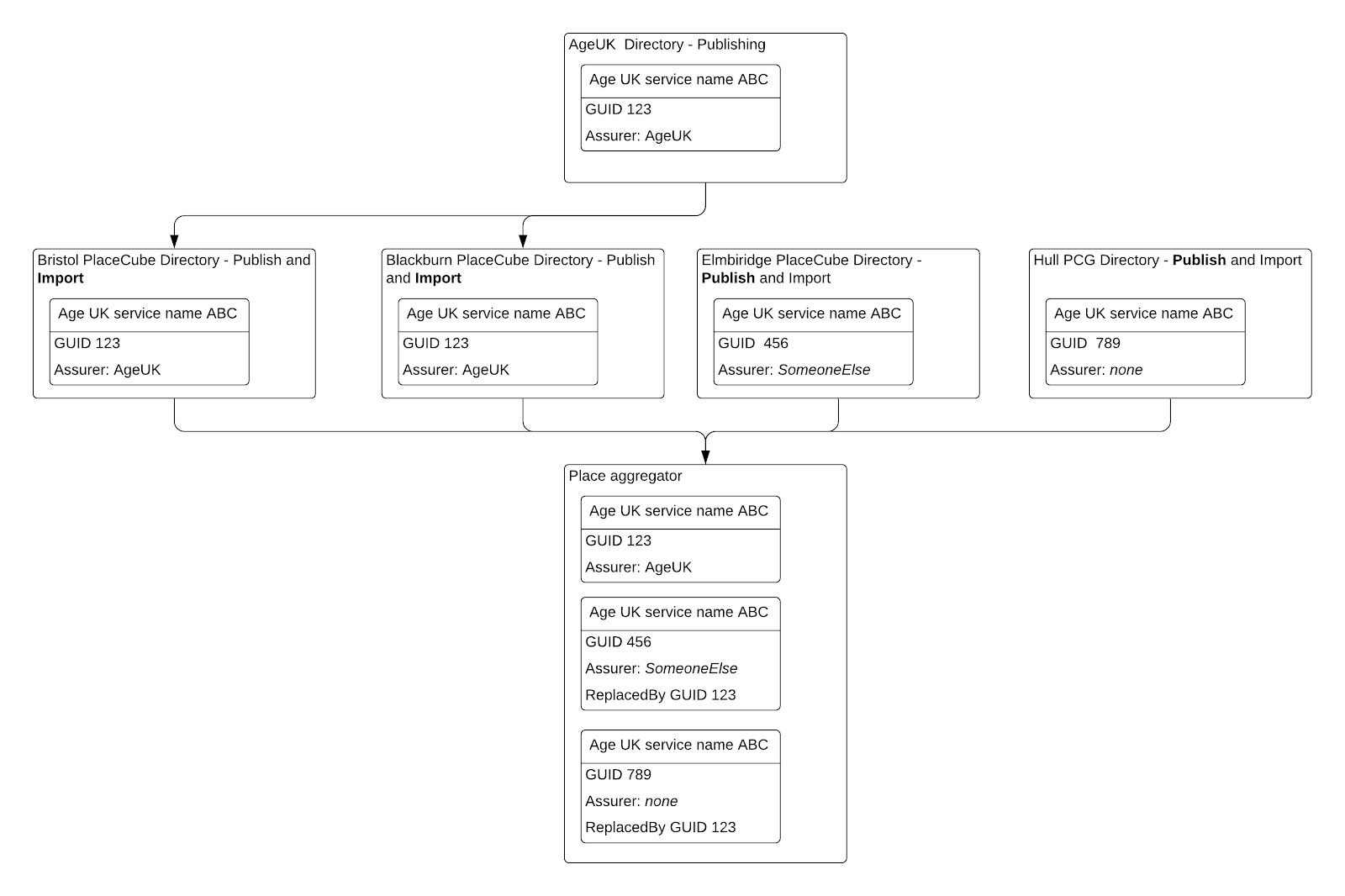
All records are read by an aggregator for the place. The aggregator needs to avoid importing the same record twice, to show preferred service records and allow access to duplicates if needed for reference (eg to copy volunteered service information to an assured record).
We need a federated structure rather than relying on central updates. Within one federated group we need to know that records can be trusted to a level set by that group.
A fuller scenario is described in Appendix A. This involves multiple user roles contributing service, location and organization details. Data custodians and aggregators need to identify and resolve duplicates.
Publishing
A data custodian will use service directory software that assigns a UUID (universally unique identifier) to every service, organization and location which originates in its directory.
| The custodian will record (normally by asking on service | location | organization input) if the person (or the organisation on behalf of which the user is acting) inputting the service is a service “owner”, “regulator”, “assurer” or none of these. Here we are calling this the record’s “provenance”. |
The custodian will be expected to allow different provenance to be assigned to service, location and organization. For example a local weight-watchers service may be run in a church hall on behalf of the national organization.
Deduplication
A data custodian and an aggregator, via service directory software, will identify similar service records and apply rules for saying which is the preferred record.
Record matching
Rules for record matching will evolve. They will include:
-
Matching identifiers using the OpenCommunity recommended extension of identifiers. Identifiers may include:
-
Organization company number
-
Organization charity commission number
-
Organization (or service?) Ofsted number
-
CQC location id
-
Location UPRN
-
Matching postcode
-
Lat/long within a certain distance from one-another
-
Web domain and email domains
-
Service organization location name and like sounding names
Removing duplicates
Identical identifiers will indicate 100% matches and rules on the provenance of records will determine which is the preferred record. Other matches will be given an approximate matching score and a manual process will be used to compare records and assign the preferred records. Other matched records will be marked as “replaced by” the preferred record.
A “Trust Register” kept by each directory that aggregates records and does such matching will log the preferred record and the “replaced by” relationships.
Hence the Trust Register will hold for every service, organization and location in a directory:
-
Its UUID
-
Its publisher (ie the data custodian responsible for creating it)
-
The UUID of the service organization location it replaces (if any)
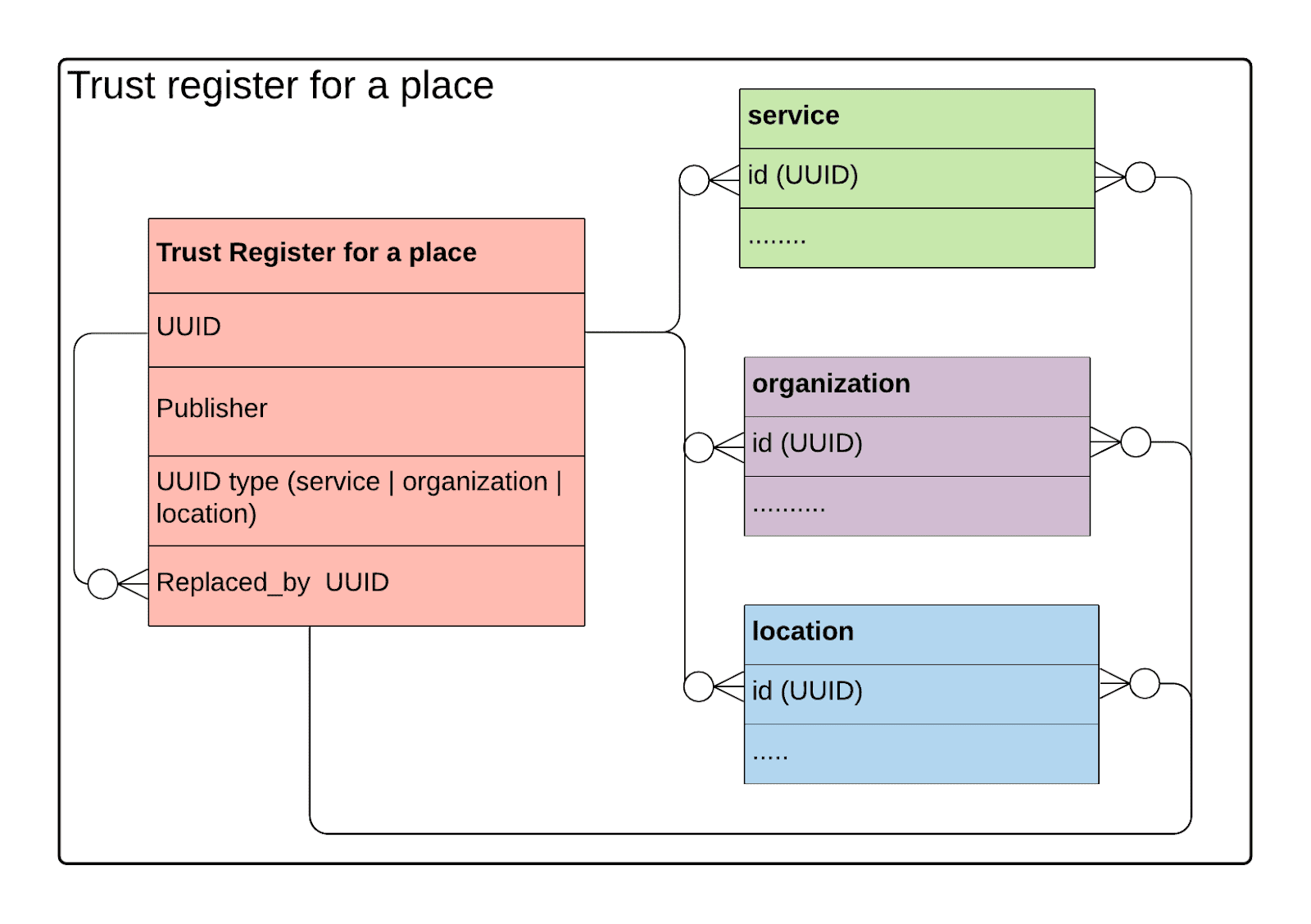
Sharing trust register entries
Each holder of a trust register will make its contents available to all publishers (via a user interface, API and/or other mechanism) such that they can see where duplicates have been identified and stop maintaining locally records for services for which there is a separate trusted source.
Viewing de-duplicated records
Queries on service directories (including aggregated ones) will, by default, only return preferred records but will indicate where a record replaces others so that a consumer might review the preferred record alongside records it replaces.
Responsibilities of data custodians
A custodian aggregating data for a “place”, must determine if directories being aggregated are of suitable quality for inclusion. A place might choose to form a group of publishers and help improve data quality.
3.1. Assuring the assurers
Data custodians will take responsibility for the assurance of their records, so their software will need to record the person or organization responsible for maintaining each record and for the quality of their assurers.
Assurers can be assessed on the number of records they assure, their validity and their richness scores.
Web methods for validating a service and assigning it a richness score are described in the document Prototyping an OpenCommunity Data Service model and in the sample API documentation.
3.2 Scope of assurance
The diagram below shows which data items fall under the control of an assurer for a service, an organization and a location.
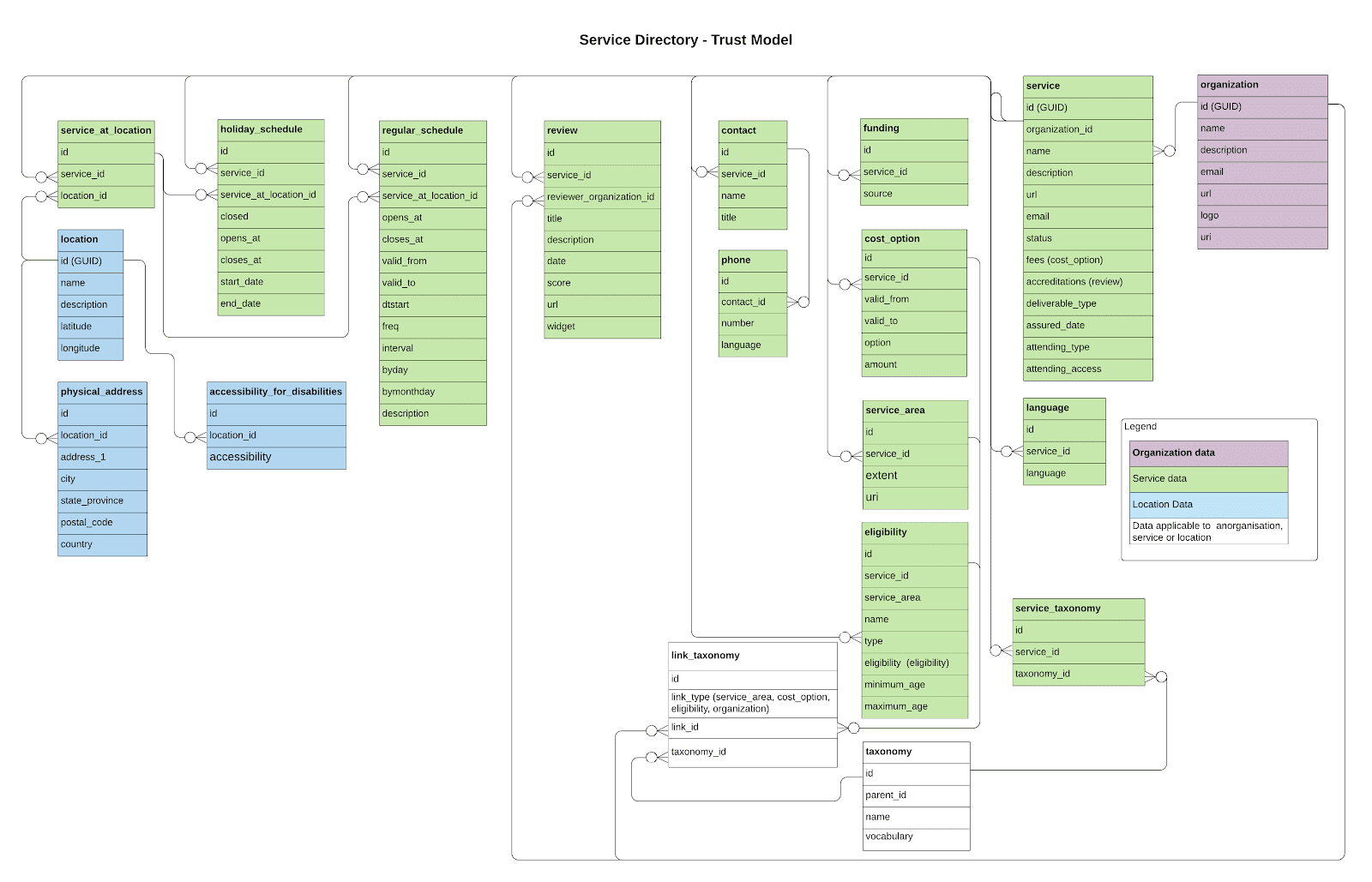
Some custodians assign responsibility for data assurance according to service type.
Implications for the data schema
As recommended by the Open Community Discovery work, a new object for identifiers is needed to allow duplicate organizations to be found.
Within a directory, a data custodian needs to record:
-
The person or organization responsible for creating and maintaining
-
The record’s assurer, which may or may not be the person responsible for its maintenance
-
The provenance of a record: “owner”, “regulator”, “assurer” or none of these
This can be achieved with a new “Provenance” object with these properties:
-
identifier
-
service | organization | location identifier
-
date
-
role (owner | regulator | assurer | none)
-
owner (organization)
We recommend adding the provenance to the schema such that this information is shared between custodians (including aggregators) and so can be used in determining the preferred record amongst duplicates.
Appendix A - Pertinent user stories
Age UK is a national organisation that has local franchises. Some things are done nationally and other things are local decisions. The following stories have not been researched with Age UK and are just to illustrate the sort of complexity of duplication that we will need to deal with. The stories are only from the roles that would be trusted to get the information correct. These stories do not deal with errors in the data. The main problem is that every trusted role could add the same service.
| Organisation | Role | Story |
|---|---|---|
| Age UK - National | Trusted Service provider | I have a service called ‘Coffee & Chat’ that we want to encourage all our local franchises to deliver to their community so I have registered the services at the HQ of each of our local franchises but not completed the session data |
| Age UK – Local | Trusted Service provider | We run a service called ‘Coffee & Chat’ that we submit full service details including location to the Trust Model |
| Age UK – local neighbour | Trusted Service provider | We run a service called ‘Coffee & Chat’ that we submit to the Trust Model but we also know that our neighbouring franchise also does one so we submit that as well as they might not know about the Trust Model |
| Community centre | Location | We host Age UK’s ‘Coffee & Chat’ so we include that as a service at our location and submit to the Trust Model |
| Community centre neighbour | Location | We host a number of services and inform the Trust Model but are also conscious of those who live on the boundary so we also inform the Trust Model about the community centre services provided there. |
| Lesley the Link worker | Trusted frontline worker | My job is to encourage people to attend ‘Coffee & Chat’ at the community centre. I want my fellow professionals to know about it so I tell the Trust Model. |
| Carol the Community connector | Trusted frontline worker | My job is to encourage people to attend ‘Coffee & Chat’ at the community centre. I want my fellow professionals to know about it so I tell the Trust Model. |
| Jim Smith | Trusted volunteer | I am a trusted volunteer and help to maintain the local service information and have noticed ‘Coffee & Chat’ advertised recently. I have obtained full details and added to the Trust Model. |
| CVS | Assurer | I have been given a grant to assure all local service information in our neighbourhoods. My team will assure all Age UK and community centre services. |
| Ethel Rimmer | Service user | I go to ‘Coffee & Chat’ each week and its great. It did used to be on Thursdays but we prefer it on a Monday now. |
| ASC directory of services | Data custodian | We pull in data from various points in our area and have to deal with duplicates. |
| Porism | Place aggregator | We aggregate all data from trusted points and have to deal with duplicates. |
| Porism | National aggregator | We aggregate data from each place aggregator so that there is a national set of trusted data. We have to deal with duplicates. |